
Les outils statistiques pour les laborantins
Les outils statistiques sont très utilisés dans un laboratoire, on les utilise quotidiennement pour évaluer certaines données ou tout simplement rendre un résultat à partir de plusieurs mesurages.
Certains nous paraissent évidents, car ils font ou faisaient partis de notre cursus scolaire, d'autres nous semblent plus difficile à utiliser par méconnaissance de leurs objectifs et de leurs cadres d’applications.
Nous allons tenter de démystifier les plus utilisés à partir d'exemples numériques:
Préambule:
Les tests ne sont pas conçus pour prouver ou réfuter des hypothèses.
L'hypothèse que nous tenterons de réfuter dans
les différents exemples est généralement toujours celle
où il n'y a pas de changement (par exemple: différence entre
deux écarts-types d'une population), c'est pour que cela nous l'appelons
l'hypothèse nulle H
Il y'a également l'hypothèse alternative H
Cette méthodologie repose sur 5 étapes distinctes:
1: Formuler le problème pratique en termes d'hypothèses
2: Calculer une statistique (T), une fonction purement issue des données. Elle doit avoir deux caractéristiques :
2.1: Elle doit se comporter différemment lorsque H
2.2: leur distribution de probabilité doit être
calculable dans l'hypothèse où H
Il est également souhaitable que les tables de distribution de cette probabilité existent.
3: Il faut choisir une tendance, nous devons être
en mesure de se prononcer sur T qui sera plutôt dirigé vers H
On ne doit jamais conclure en acceptant H
4:Il faut déterminer le niveau du
risque α, c'est le risque que l'on prend si on rejette l'hypothèse
H
Il est également possible de ne pas rejeter H

5: Examiner si la valeur de T se situe proche de la prise de non décision ou bien est très largement dans les conditions des tables de distribution.
La grande majorité des tests considèrent que les distributions sont normales.
Les applications numériques peuvent parfois utiliser des erreurs aberrantes par rapport à la performance des équipements, il s'agit avant tout de montrer les difficultés sur la prise de décision.
![]()
Rappel d'une Loi normale:
La Loi normale ou gaussienne (distribution) occupe une place importante dans les statistiques et les mesures. Sa courbe familière en forme de cloche permet de calculer la probabilité de trouver un résultat dans une fourchette donnée. L'axe des abscisses correspond à la valeur de la variable considérée et l'axe des y est la valeur de la densité de probabilité.
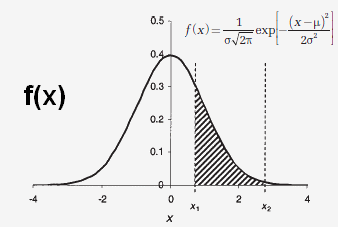
L'aire hachurée représente la probabilité
de la valeur entre les bornes x
µ représente l'espérance mathématique (la moyenne) et la largeur de la distribution est donnée par la variance σ², la racine carrée de la variance correspond à l'écart type σ des valeurs pour obtenir la moyenne.
Moyenne et écart-type:
Supposons n = 10 mesurages qui donnent les valeurs suivantes:
| 10,2 |
9,7 |
10,3 |
10,1 |
9,8 |
10,5 |
10,0 |
9,6 |
10,4 |
9,5 |
La moyenne donnée par:
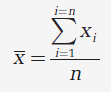
x̄ est l'estimation de µ et vaut: 10,01
L'écart-type est donné par:
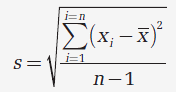
s est une estimation de σ et vaut: 0,348
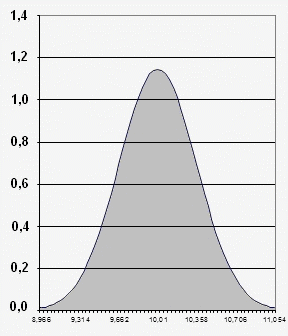
En calculant f(10,01), on trouve 1,146 et f(10,5)= 0,425 =LOI.NORMALE(10,5;10,01;0,348;FAUX) [EXCEL] pour déterminer la gaussienne.
Supposons maintenant que cette série de 10 mesurages est répétée un grand nombre de fois. La moyenne de toutes les valeurs de x tend vers la moyenne µ de la population.
L'écart-type moyen de la population est donné par:
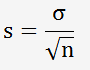
La variance est le carré de l'écart-type: s²
![]()
Z-Test sur la moyenne d'une population (variance connue)
Objectif: pour étudier l'importance
de la différence entre la moyenne µ
Contraintes: connaître la variance du process σ², la distribution doit être normale.
Problème: une burette automatique
délivre 400 µl de réactif (µ
Mensuellement, l'opérateur réalise 10 mesures du volume versé, il trouve une moyenne x̄ = 406 µl.
Que peut-on penser de la qualité de distribution de la burette?
Hypothèses et alternatives:
Scénario N°1 H
Scénario N°2 H
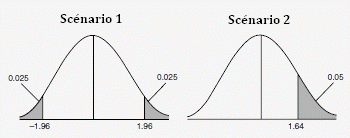
Prise de risque: α = 0,05 (unilatérale et bilatérale:0,025)
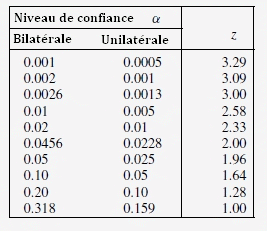
La Table des valeurs critiques pour une distribution normale donne pour α = 0,05: Z = 1,64 (unilatérale) et α = 0,05: Z = 1,96 (bilatérale)
Test statistique:
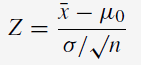
Z = 1,9
Conclusion:
Pour le scénario 1 (distribution bilatérale),
Le Z-test est compris entre -1,96 et + 1,96, l'hypothèse nulle H
Pour le scénario 2 (distribution unilatérale),
le Z-test est supérieur à 1,64 et l'hypothèse nulle H
![]()
t-Test sur la moyenne d'une population (variance inconnue)
Objectif: pour étudier l'importance
de la différence entre la moyenne µ
Contraintes: la distribution doit être normale, l'échantillonnage doit être de petite taille (n<20).
Problème: une burette automatique
délivre un volume fixe moyen (µ
Le certificat de l'équipement nous annonce une valeur moyenne x̄ = 400 µl.
Que peut-on penser de la qualité de distribution de la burette?
Hypothèses et alternatives:
Scénario N°1 H
Prise de risque: α = 0,05 (bilatérale:0,025)
La Table des valeurs critiques pour
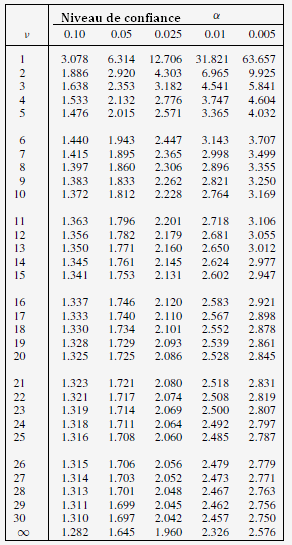
une distribution de Student donne pour α = 0,05 et ν=9-1=8
degrés de liberté donc t
Test statistique:
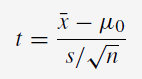
t = 3,75
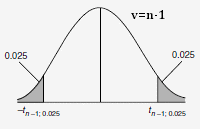
Conclusion:
Pour le scénario avec une distribution bilatérale,
le t est supérieur à 2,3 et l'hypothèse nulle H
![]()
Z-Score
Objectif: le Z-score est utilisé pour comparer une valeur à une population, si le Z-score est inférieur ou égal à 2.0 (probabilité de 95%), on peut conclure de la justesse d’une méthode ou de la valeur dans le niveau de gamme considéré.
Contraintes:/
Problème:
Calcul du Z-score d'un laboratoire par rapport aux 10 résultats
obtenus lors d'un essai interlaboratoires: x
| 10,2 |
9,7 |
10,3 |
10,1 |
9,8 |
10,5 |
10,0 |
9,6 |
10,4 |
9,5 |
Prise de risque:α = 0,05
Test statistique:
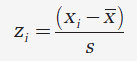
x
Conclusion:
Le Z-score est inférieure à 2, la valeur est satisfaisante.
![]()
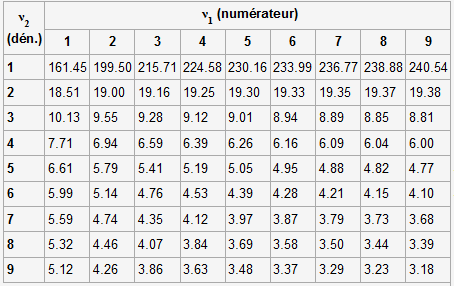
Test de Fisher F (2 variances)
Objectif: ce test permet d'étudier
l'importance des variances de deux séries de mesures provenant de deux
process indépendants (P1 et P2), la variance la plus forte est toujours
mise au numérateur: s
Contraintes: il est limité à deux séries de mesures qui doivent avoir une distribution normale.
Problème: un laboratoire a mis en
place un nouvel équipement (P2) et espère obtenir avec ce nouveau
process, un écart-type s
Que peut-on dire sur les deux variances de ces deux populations? Est-il probable qu'elles diffèrent?
Hypothèses et alternatives:
Scénario H
Test statistique:
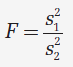
| N° | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | x̄ | s |
| P1 | 10.2 |
9.7 |
10.3 |
10.1 |
9.8 |
10.5 |
10.0 |
9.6 |
10.4 |
9.5 |
10.01 | 0.348 |
| P2 | 11.3 | 11.1 | 11.5 | 11.5 | 11.0 | 11.4 | 11.3 | / | / | / | 11.30 | 0.191 |
s
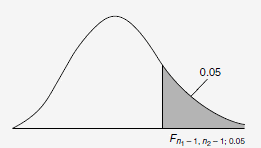
F doit être comparé à la Table de Fisher-Snedecor qui nécessite de connaitre les degrés de liberté de chacune des séries et dans notre cas, nous avons respectivement 10 et 7 valeurs donc ν1=10-1=9 et ν2=7-1=6.
La table donne une valeur critique Fc = 4,10, ce qui est supérieur à 3.3, cela signifie que l'hypothèse nulle ne peut pas être rejetée, le laboratoire ne peut donc affirmer avec une confiance de 95% que son nouvel équipement fournisse un écart-type plus petit.
![]()
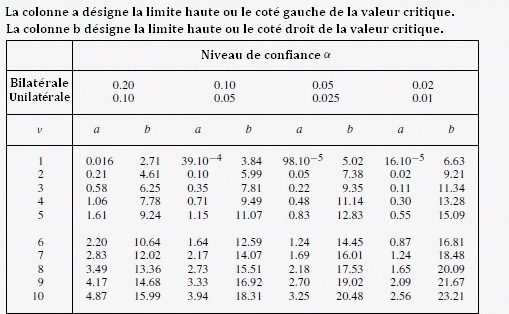
Test du khi²
Objectif: Pour étudier la différence entre un échantillon de variance s et la variance d'une population σ.
Contraintes: il est supposé que les valeurs de l'échantillon suivent une loi normale.
Problème: je réalise 10 mesurages sur un échantillon E1, ce qui me donne un écart-type de s=3,46.
Le suivi régulier de l'échantillon E1 sur plusieurs mois me donne un écart-type de σ=3,01.
La variabilité de mon échantillon à t-elle changée?
Hypothèses et alternatives:
Scénario N°1 H
Scénario N°2 H
Prise de risque: α = 0,05
Test statistique:
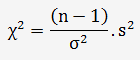
Soit s l'écart-type de mon laboratoire avec 9 degrés de liberté (10-1) et σ l'écart-type de la population.
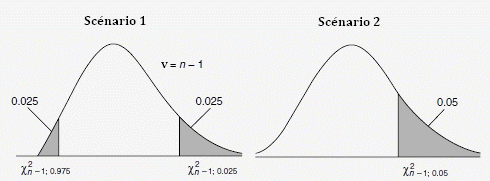
En consultant la Table du chi², on constate que pour un nombre de degré de liberté de 9 et une probabilité de 95%, le chi²= [2,70;19,02] pour le scénario 1 et le chi²= [3,33;16,92] pour le scénario 2, la valeur du chi² est comprise entre les bornes, l'hypothèse nulle ne peut pas être rejetée, la différence entre les deux variances n'est pas significative, mon échantillon n'a pas changé.
![]()
Table des valeurs critiques pour une distribution normale
![]()
Table des valeurs critiques pour une distribution de student
![]()
![]()
![]()